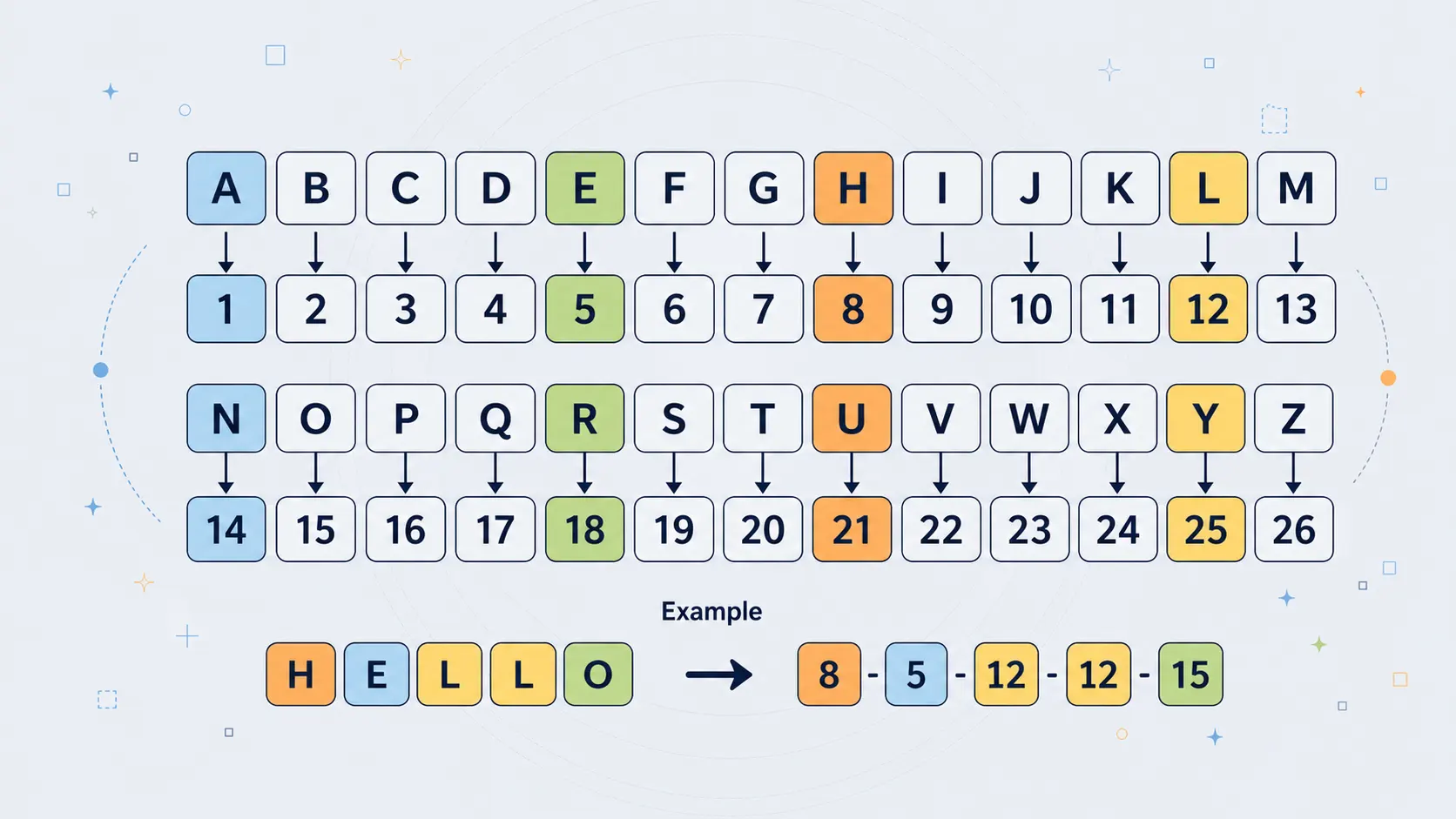
A1Z26 replaces letters with their positions in the alphabet: A = 1, B = 2, C = 3, all the way to Z = 26. It is one of the clearest possible examples of symbolic transformation.
A1Z26 at a Glance
The A1Z26 cipher is one of the simplest and most intuitive ways to disguise text. Instead of shifting letters, scrambling alphabets, or using a secret keyword, it takes each letter and replaces it with its numerical position in the alphabet. A becomes 1, B becomes 2, C becomes 3, and so on until Z becomes 26.
At first glance, it hardly seems like a cipher at all. It looks more like a classroom exercise, a puzzle convention, or a child's first code. And yet that first impression is exactly what makes it so valuable. A1Z26 exposes one of the deepest ideas in cryptography in an almost transparent form: symbols can be transformed according to a rule and then recovered by reversing that rule.
If the plaintext is:
HELLO
then under A1Z26 it becomes:
8-5-12-12-15
If the recipient knows the rule, the message can be turned back into letters immediately. That simple reversibility is what gives the method its appeal. It is not strong, but it is clean. It is not subtle, but it is memorable. It makes the transformation from readable language to coded form visible in a way that more sophisticated ciphers often do not.
In that sense, A1Z26 sits in an interesting position. It is often called a cipher, and in a broad teaching sense that is fair enough. It does substitute one symbol for another. But it is also so direct, so literal, and so lacking in secret structure that it often feels closer to an encoding convention than to serious encryption. There is usually no real key. There is no hidden alphabet. There is no variable rule. It simply relabels letters as numbers.
That is precisely why it is worth studying. A1Z26 makes it possible to see the bones of substitution without distraction. It is one of the easiest systems with which to explain plaintext, ciphertext, reversibility, ambiguity, symbol mapping, and the limits of naive secrecy. It teaches not only what a code can do, but what it fails to do.
It also has a surprisingly broad cultural footprint. A1Z26 appears in puzzles, treasure hunts, school exercises, escape rooms, hobbyist cryptography, internet games, and stylised secret messages. It is the kind of method people discover independently because it feels so natural. Once you realise that the alphabet has an order, the temptation to turn that order into numbers is almost automatic.
There is another reason it remains appealing: numbers look more mysterious than letters. A row of digits can create the impression of hidden depth even when the underlying rule is extremely simple. That visual shift matters. A message like:
20-8-5 13-5-5-20-9-14-7 9-19 1-20 14-9-14-5
looks secret in a way that plain words do not, even though it is only:
THE MEETING IS AT NINE
That contrast between appearance and actual security is one of the central lessons of classical cryptography. A1Z26 teaches it beautifully. It demonstrates how easy it is to produce the feeling of secrecy, and how different that is from genuine resistance to attack.
In the clearest terms, then, A1Z26 is a direct letter-to-number substitution system in which each letter is replaced by its position in the alphabet. It is simple, readable, highly learnable, and cryptographically weak, but it remains one of the best introductory examples of symbolic encoding and elementary cipher logic.
How the Number Mapping Works
The A1Z26 cipher works by assigning each letter of the alphabet a number based on its position.
The mapping is:
| Letter | Number | Letter | Number | Letter | Number | Letter | Number |
|---|---|---|---|---|---|---|---|
| A | 1 | H | 8 | O | 15 | V | 22 |
| B | 2 | I | 9 | P | 16 | W | 23 |
| C | 3 | J | 10 | Q | 17 | X | 24 |
| D | 4 | K | 11 | R | 18 | Y | 25 |
| E | 5 | L | 12 | S | 19 | Z | 26 |
| F | 6 | M | 13 | T | 20 | ||
| G | 7 | N | 14 | U | 21 |
To encrypt a message, each letter is replaced by its corresponding number. That is the entire mechanism.
For example, take the word:
CAT
The letters become:
C -> 3A -> 1T -> 20
So:
CAT -> 3-1-20
That is A1Z26 in its purest form.
A slightly longer example makes the pattern even clearer. Suppose the plaintext is:
SECRET
Then the conversion is:
S -> 19E -> 5C -> 3R -> 18E -> 5T -> 20
So the ciphertext becomes:
19-5-3-18-5-20
Decryption is simply the reverse process. You read each number and convert it back into the corresponding letter.
So if you receive:
3-15-4-5
you read:
3 -> C15 -> O4 -> D5 -> E
giving:
CODE
That is what makes the system so approachable. Nothing changes from one letter to the next. There is no rotating disk, no keyword, no modular arithmetic, no changing alphabet. There is only a stable lookup between letters and positions.
In practice, separators matter. A message such as:
8 5 12 12 15
is easy to read as HELLO because each number is clearly separated. But if you write:
85121215
the structure becomes much less obvious. Is it:
8-5-12-12-15 -> HELLO
8-5-1-21-21-5 -> HEAUUE
8-5-12-1-2-15 -> HELABO
Without separators, ambiguity rapidly appears. This is one of the system's most important practical issues. A1Z26 looks clean when numbers are neatly divided, but once those boundaries disappear the decoding process can become messy.
A common modern presentation uses hyphens between letters and spaces or slashes between words:
HELLO WORLD -> 8-5-12-12-15 / 23-15-18-12-4
HELLO WORLD -> 8-5-12-12-15 23-15-18-12-4
Some versions use commas, dots, or other separators. The exact punctuation is a matter of convention, but some visible form of separation is usually essential if the message is to remain readable.
Because of that, A1Z26 has an unusual feel compared with many classical ciphers. It does not merely replace letters; it also often needs a formatting system to keep the result intelligible. That means presentation is not just cosmetic. It is part of how the cipher remains usable.
So in practical terms, A1Z26 works by mapping each letter to its alphabetical index, writing the resulting numbers in sequence, and preserving enough separation that the message can later be reconstructed. The logic is simple, but the mechanics of formatting are more important than they first appear.
Core Rules, Conventions, and Presentational Choices
A1Z26 is one of the simplest ciphers to understand, but even simple systems acquire rules once people start using them seriously. Most of the confusion does not come from the alphabet-to-number mapping itself. It comes from the surrounding questions: how do you separate letters, what happens to spaces, what about punctuation, how do you handle lowercase, and what do you do with numbers already present in the message?
The central rule is easy:
Each letter is replaced by its position in the alphabet.
That part never changes in standard A1Z26. There is no numerical key in the usual version. The transformation is fixed from beginning to end.
But after that, conventions matter.
Separators Between Letters
This is the most important presentational rule in A1Z26. Since some letters are represented by one digit and others by two digits, the output can become ambiguous unless the numbers are separated.
For example:
BAD -> 2-1-4
is clear.
But:
214
could be read in several ways unless the reader already knows how it is grouped. That is why hyphens are so common. They preserve the one-letter-to-one-number relationship visibly.
Word Separation
Words may be separated by spaces, slashes, or some other marker.
For example:
MEET ME -> 13-5-5-20 13-5
MEET ME -> 13-5-5-20 / 13-5
Both are fine as long as the method is consistent.
Case
A1Z26 usually ignores case. Uppercase and lowercase letters map to the same values.
A = 1
a = 1
This means Hello, HELLO, and hello all become:
8-5-12-12-15
unless some special formatting layer is added.
Punctuation
Punctuation may be preserved, removed, or marked separately.
For example:
RUN! -> 18-21-14!
RUN! -> 18-21-14
Neither is intrinsically more correct. It depends on the style of the tool or article. But consistency matters.
Numbers Already in the Plaintext
This is one of the trickier practical issues. What should happen if the original message already contains digits?
Take:
MEET AT 9
A1Z26 can handle that in different ways:
- preserve the
9as literal text - remove it
- mark it specially
- convert it through some additional rule outside standard A1Z26
Most implementations simply leave numbers unchanged. But that means the ciphertext mixes encoded numbers and literal numbers, which can create confusion unless the formatting is clear.
For example:
MEET AT 9 -> 13-5-5-20 1-20 9
The final 9 here could mean the literal digit nine, or it could be read as the letter I if context is unclear.
That ambiguity is not a minor detail. It reveals a deeper point: A1Z26 has weak symbol boundaries unless the designer imposes them carefully.
Alphabet Assumptions
A1Z26 assumes a standard 26-letter English alphabet. Once accented letters, non-English alphabets, ligatures, or special characters appear, the system either has to ignore them or be expanded.
That makes it neat for English teaching examples, but less universal than it first appears.
No Real Secret Key
Unlike Caesar or Vigenère, standard A1Z26 does not ordinarily use a secret key. That means anyone who recognises the system can decode it instantly.
This is one reason many people describe it as more of an encoding scheme than a serious cipher. It transforms text, but it does not usually hide the rule of transformation.
In short, the rules of A1Z26 are simple but not entirely trivial:
- convert letters to numbers
1through26 - separate them clearly
- decide how to mark word boundaries
- handle punctuation consistently
- handle existing digits consistently
- assume a 26-letter alphabet unless explicitly stated otherwise
These decisions are small, but they strongly affect how readable, ambiguous, or fragile the result becomes.
A Step-by-Step Example
The easiest way to understand A1Z26 is to watch a full message move from plain text into numbered form and then back again.
Let the plaintext be:
ATTACK AT DAWN
Now convert each letter one at a time.
First word: ATTACK
A -> 1T -> 20T -> 20A -> 1C -> 3K -> 11
So:
ATTACK -> 1-20-20-1-3-11
Second word: AT
A -> 1T -> 20
So:
AT -> 1-20
Third word: DAWN
D -> 4A -> 1W -> 23N -> 14
So:
DAWN -> 4-1-23-14
Put together, the full ciphertext becomes:
1-20-20-1-3-11 1-20 4-1-23-14
Seen in parallel, it looks like this:
Plaintext: ATTACK AT DAWN
Ciphertext: 1-20-20-1-3-11 1-20 4-1-23-14
The reverse process is just as direct.
Suppose someone receives:
1-20-20-1-3-11 1-20 4-1-23-14
and knows the A1Z26 mapping.
They decode it as follows:
First word:
1 -> A20 -> T20 -> T1 -> A3 -> C11 -> K
So:
1-20-20-1-3-11 -> ATTACK
Second word:
1 -> A20 -> T
So:
1-20 -> AT
Third word:
4 -> D1 -> A23 -> W14 -> N
So:
4-1-23-14 -> DAWN
Recovered message:
ATTACK AT DAWN
This example reveals something important. The same letter always becomes the same number. Every A is 1. Every T is 20. Every N is 14. In that sense A1Z26 is a monoalphabetic substitution system, just like many more famous classical ciphers.
But it also shows a peculiarity of A1Z26: the ciphertext is often more visibly structured than the plaintext. Repeated letters remain repeated values. Common letters remain common numbers. Word boundaries often remain visible. And unless extra effort is made, the resulting number stream can look orderly rather than hidden.
That makes the system easy to use, but also easy to recognise.
Where A1Z26 Comes From
Unlike the Caesar cipher, the A1Z26 system is not strongly attached to one famous historical figure or one dramatic ancient anecdote. It has a more diffuse origin. It emerges naturally from the alphabet itself.
Once an alphabet is ordered, assigning numbers to letters is almost inevitable. A is first, B is second, C is third. The step from that observation to a usable code is very small. For that reason, A1Z26 belongs less to one specific inventor than to a broader human instinct: the urge to turn symbols into ordered values and then use those values for concealment, indexing, or play.
That matters because A1Z26 is often rediscovered rather than formally taught. People encounter the ordered alphabet as children. They learn that letters have positions. Soon after, they realise those positions can stand in for the letters themselves. In that sense A1Z26 feels almost primordial. It is one of the first "secret code" ideas that springs to mind.
Its historical role is therefore somewhat different from that of more formal ciphers. Caesar, Vigenère, Playfair, and Hill belong to traditions of explicit cryptographic design. A1Z26 belongs more to the borderland between education, notation, puzzles, and amateur cryptography.
It has appeared in many settings:
- school exercises involving alphabet order
- puzzle books and treasure hunts
- code games between children
- hobby cryptography manuals
- numerological or symbolic letter-number systems
- internet riddles and alternate-reality style clues
That wide spread tells us something important. A1Z26 survives not because it was ever a major military or diplomatic cipher, but because it is structurally obvious. It is the kind of system human beings invent again and again.
There is also a conceptual history here. Before modern computing, before formal information theory, and before sophisticated encryption, people repeatedly discovered that meaning can be detached from its surface form. Letters can become symbols, symbols can become numbers, and numbers can travel where words might attract attention. A1Z26 captures that transformation in an unusually stark way.
For that reason, it belongs to the long prehistory of information coding as much as to cryptography proper. It is a reminder that secret writing does not begin with advanced mathematics. It begins with substitution, abstraction, and the recognition that one representation can stand in for another.
So although A1Z26 lacks the glamorous biography of some classical ciphers, it has a kind of universality instead. It is one of the simplest possible bridges between language and arithmetic, and that alone has guaranteed its survival.
Why It Can Feel Cleverer Than It Is
Part of the charm of A1Z26 is psychological. A line of numbers looks more hidden than a line of letters. Even when the mapping is obvious, the result carries a faint aura of system, machinery, and secret order.
That effect should not be underestimated. Much of early cryptography relied not only on actual concealment but on perceived difficulty. If a message does not look like ordinary language, many readers will stop there. The barrier of unfamiliar form can be enough to deter casual inspection.
A1Z26 benefits from that effect powerfully. Consider the difference between these two lines:
MEET AT THE GATE
13-5-5-20 1-20 20-8-5 7-1-20-5
The second looks encoded, technical, perhaps even mathematical. Yet it is only a direct relabelling of letters.
This is why A1Z26 works well in lightweight settings:
- simple note-passing
- puzzle clues
- classroom demonstrations
- beginner cryptography tools
- playful hidden messages
It offers just enough transformation to create distance from the original text.
It is also satisfying because it allows language to be handled almost like data. Words become sequences. Letters become values. Text becomes something that can be counted, grouped, split, and inspected numerically. That gives A1Z26 a distinctly analytical flavour. It feels like a first step from writing into information processing.
That is one reason it suits science-magazine style explanation so well: it sits right at the junction of language, mathematics, and symbolic systems. It is not deep cryptography, but it is a vivid example of how easily meaning can migrate from one form into another.
Where the Method Breaks Down
A1Z26 is elegant, but it is also fragile. Its weaknesses are not accidental side issues. They arise directly from the fact that the method is so literal.
It Usually Has No Secret Key
This is the biggest problem. In standard form, A1Z26 does not depend on hidden information. Anyone who recognises the mapping can reverse it immediately.
A cipher without a secret rule is barely a cipher at all in the security sense.
It Preserves Letter Frequencies
Common letters in English become common numbers.
So if E is common in plaintext, 5 will be common in ciphertext. If T is common, 20 will appear frequently. The statistical shape of the language remains visible.
It Preserves Repetition
Repeated letters stay repeated values.
For example:
LETTER -> 12-5-20-20-5-18
The double T becomes double 20. That kind of visible structure is useful to an attacker.
Word Patterns Often Survive
If spaces are preserved, word lengths remain visible. Short words such as A, I, AN, TO, and THE become easy to guess from context and repeated patterning.
It Can Be Ambiguous Without Separators
Because the numbers have varying lengths, a continuous stream can become difficult to decode cleanly.
For example:
111520
could potentially be segmented in many ways. Unless the boundaries are known, decryption becomes uncertain. This is a weakness of clarity rather than secrecy, but it still matters.
It Handles Mixed Content Awkwardly
Plaintext that includes digits, punctuation, accented letters, or symbols requires extra rules. Without them, the output can become inconsistent or confusing.
It Is Instantly Recognisable
A row of numbers between 1 and 26, especially separated by hyphens, practically announces what it is. That makes it poor for concealment against anyone even slightly familiar with puzzles or classical ciphers.
So A1Z26 is weak for two different reasons at once:
- it is easy to reverse once recognised
- it sometimes becomes ambiguous if formatted badly
That is an interesting combination. Many ciphers fail because they are too hard to protect. A1Z26 can fail either because it is too easy to break or because it is too sloppy to decode neatly.
How It Is Cracked
Strictly speaking, "cracking" A1Z26 is often too grand a word. In many cases the message is not broken through elaborate cryptanalysis; it is simply read.
If the ciphertext is:
8-5-12-16
an informed reader will immediately try the obvious conversion:
8 -> H5 -> E12 -> L16 -> P
giving:
HELP
That is not really an attack. It is recognition.
Still, there are several ways the system can be defeated.
- Direct recognition: Numbers from
1to26with clear separators strongly suggest alphabet indexing. - Frequency clues: If a long ciphertext contains many
5s,20s,1s, and15s, an attacker may suspect common English letters such asE,T,A, andO. - Pattern guessing: A repeated sequence such as
20-8-5may suggestTHE, especially in English text. - Contextual guessing: If the message appears in a puzzle, classroom sheet, or beginner cipher site, A1Z26 is one of the first methods an attacker will test.
- Boundary inference: Even if separators are removed, a patient attacker can try plausible segmentations because only
1through26are valid values.
That last point is worth pausing on. Removing separators can make A1Z26 harder to read, but not necessarily much safer. It replaces immediate legibility with a solvable parsing problem. On longer messages, likely word structures and letter frequencies usually restore the missing divisions.
So A1Z26 is broken not by rare genius but by ordinary familiarity. Its logic is too transparent, its mapping too standard, and its output too revealing to resist even basic analysis.
Ciphers and Systems Closely Related to A1Z26
A1Z26 sits inside a much broader family of symbolic transformations. Seeing those neighbours helps clarify what it is and what it is not.
Caesar cipher: The Caesar cipher also depends on alphabet order, but instead of replacing letters with numbers, it shifts them by a fixed amount. So if A1Z26 is "alphabet position written out directly," Caesar is "alphabet position moved and then converted back into letters."
Affine cipher: The Affine cipher treats letters as numbers under the hood and transforms them mathematically before mapping them back to letters. In that sense, A1Z26 is like the bare skeleton of a more mathematical cipher tradition.
Vigenère cipher: Vigenère can be understood as a changing sequence of Caesar shifts. Again, the alphabet becomes arithmetic behind the scenes. A1Z26 is far simpler, but it helps build the intuition that letters can be treated numerically.
Polybius square: This is a particularly close cousin in spirit. The Polybius square also converts letters into numbers, though usually as coordinate pairs such as 11, 12, 13, and so on. Compared with A1Z26, it is more structured and often slightly less immediately transparent.
ASCII and digital encodings: In a modern sense, A1Z26 also gestures toward a much larger world. Computers routinely turn letters into numbers. ASCII, Unicode, and every digital text system do exactly that, though in far more systematic ways. A1Z26 is not a computing standard, but it is a beginner-friendly glimpse of the same principle: text can be represented numerically.
Numerological letter systems: Outside formal cryptography, many traditions assign numerical values to letters for symbolic or mystical purposes. Those systems are not necessarily ciphers at all, but they share the same foundational move: linking language to number through alphabetic position or assigned value.
This wider context is one reason A1Z26 matters. It is not just a toy code. It is a very simple instance of a broad and powerful idea: symbols can be mapped into numerical space.
Why It Still Matters
A1Z26 still matters because it is one of the clearest demonstrations of symbolic substitution available to beginners.
It teaches several lessons at once.
It shows that language can be encoded. A word is not tied to one appearance. It can be represented in another system while remaining recoverable.
It introduces reversible transformation. Good beginner ciphers teach not just secrecy but reversibility. A1Z26 does that perfectly. Every valid encoding can, in principle, be turned back into text.
It highlights the difference between encoding and encryption. This may be its most valuable conceptual lesson. A1Z26 looks secret, but it offers very little actual security. That makes it ideal for teaching the difference between merely changing form and genuinely protecting information.
It connects language with arithmetic. Many beginners are startled, in a good way, by the fact that text can be treated numerically. A1Z26 offers an easy entrance into that way of thinking.
It is excellent for coding practice. A small A1Z26 tool teaches character handling, lookup tables, string splitting, validation, formatting rules, and edge-case handling. For a programmer, it is a neat introductory project because the core logic is tiny but the practical details are surprisingly rich.
It survives in puzzles and popular culture. Because it is solvable, recognisable, and satisfying, A1Z26 remains useful anywhere playful secrecy is wanted.
In a larger sense, A1Z26 matters because it dramatises a deep truth about information: meaning is not the physical form of a message. Meaning can move. Letters can become numbers. Numbers can become letters again. That is a small idea when done as a puzzle, and a civilisation-defining idea when scaled into modern communication systems.
The Real Lesson of A1Z26
What makes A1Z26 interesting is not that it is powerful. It is not. It is not even especially deceptive once you know what to look for.
What makes it interesting is that it reveals, in almost laboratory form, the basic moves from which more serious cryptography grows.
Take a message.
Replace each symbol according to a rule.
Preserve enough structure to reverse the process.
Then ask the crucial question:
has the message merely changed shape, or has it actually become secure?
A1Z26 gives a crisp answer. It has changed shape. That alone is fascinating, useful, and educational. But it is not enough.
That is why the method belongs on any good classical cipher site. It is simple enough to master in minutes, clear enough to teach real ideas, and weak enough to force the right conceptual distinction. It does not merely teach coding. It teaches scepticism about coding.
In the end, A1Z26 is best understood as a gateway system: part puzzle, part notation, part cipher, part lesson in the limits of superficial secrecy. It turns the alphabet into arithmetic, makes hidden messages feel possible, and then quietly shows why true cryptography had to go much further.
A Small Python Example
One reason the A1Z26 cipher remains such a useful beginner system is that it translates very naturally into code. The underlying rule is simple, the transformation is reversible, and the result is easy to test. That makes it an ideal first exercise for anyone learning about both classical ciphers and basic text processing.
In its simplest form, the cipher only needs one fixed mapping: each letter is replaced by its position in the alphabet. In Python, that can be done by reading the message one character at a time, converting letters into numbers from 1 to 26, and then joining those values into a readable sequence.
Here is a compact example that encrypts ordinary text into A1Z26 form and then decrypts it back again:
Python exampleShow code
def a1z26_encrypt(text):
words = []
for word in text.upper().split():
numbers = []
for char in word:
if char.isalpha():
numbers.append(str(ord(char) - ord('A') + 1))
words.append('-'.join(numbers))
return ' / '.join(words)
def a1z26_decrypt(code):
words = []
for word in code.split(' / '):
letters = []
for number in word.split('-'):
if number.isdigit():
value = int(number)
if 1 <= value <= 26:
letters.append(chr(ord('A') + value - 1))
words.append(''.join(letters))
return ' '.join(words)
message = "HELLO WORLD"
encrypted = a1z26_encrypt(message)
decrypted = a1z26_decrypt(encrypted)
print("Plaintext :", message)
print("Encrypted :", encrypted)
print("Decrypted :", decrypted)
If this script is run, the output will be:
Plaintext : HELLO WORLD
Encrypted : 8-5-12-12-15 / 23-15-18-12-4
Decrypted : HELLO WORLD
The encryption function works by taking the input text, converting it to uppercase, splitting it into words, and then examining each character in turn. If the character is a letter, its alphabetical position is calculated and stored as a number. The numbers for each word are joined with hyphens, and the words themselves are separated with a slash. This keeps the ciphertext readable and avoids the ambiguity that would arise if all the digits were written as one continuous string.
The decryption function simply reverses that process. It begins by splitting the ciphertext into words, then splitting each word into its component numbers, and finally converting each valid number back into its corresponding letter. Once all the letters have been reconstructed, the original message reappears.
What makes this example useful is not just that it works, but that it exposes several important ideas very clearly. It shows how letters can be treated as numerical values, how a cipher can be reversed by applying the opposite mapping, and how formatting conventions such as separators are essential to making an encoded message readable again. Even in a cipher as simple as A1Z26, presentation is not an afterthought. It is part of the design.
This also helps explain why A1Z26 is such a good teaching tool for programmers. The core logic is tiny, but it opens naturally into bigger questions: how should punctuation be handled, what should happen to digits already present in the plaintext, should lowercase be preserved, and how should invalid ciphertext be treated? In that sense, writing an A1Z26 encoder is not just an exercise in toy cryptography. It is also a neat introduction to the practical discipline of turning symbolic rules into working code.
A1Z26 may be cryptographically weak, but as a compact programming exercise it is almost ideal: simple enough to understand immediately, structured enough to reward careful thinking, and rich enough to show the difference between a code that merely transforms text and a system designed to protect it.