ROT13 is easy to defeat, yet it remains one of the clearest and most memorable ways to begin learning cryptography.
ROT13 at a Glance
ROT13 is a simple substitution cipher in which each letter is replaced by the letter 13 places further along in the alphabet. The name stands for "rotate by 13". If you start with A, you move 13 places and get N. If you start with B, you get O. The pattern continues all the way through the alphabet until M becomes Z, and then the second half wraps back around so that N becomes A, O becomes B, and Z becomes M.
That makes ROT13 a special case of the Caesar cipher, which is the broader family of ciphers that shift letters by a fixed number. Caesar's own historical shift was usually described as 3, but ROT13 fixes the shift at 13 and never changes it.
What makes ROT13 unusual is that it sits exactly halfway around the 26-letter alphabet. Because of that, the same operation both encrypts and decrypts. Apply it once and plaintext becomes ciphertext. Apply it again and the ciphertext returns to plaintext. In that sense, ROT13 is less like a secret code with a variable key and more like a fixed transformation.
It is important to understand from the beginning that ROT13 is not a serious security method. It was never suitable for protecting confidential information from a determined reader. Its purpose is better described as obscuring text rather than truly securing it. It hides something from casual glance, but not from anyone who actively wants to read it.
Even so, ROT13 is still worth learning. It is one of the clearest possible introductions to how substitution ciphers work. It shows how readable text can be transformed into another form, how wrapping around the alphabet works, and how a cipher can be reversible. For beginners, it is often the first cipher that makes the basic ideas of cryptography feel concrete.
The Core Idea
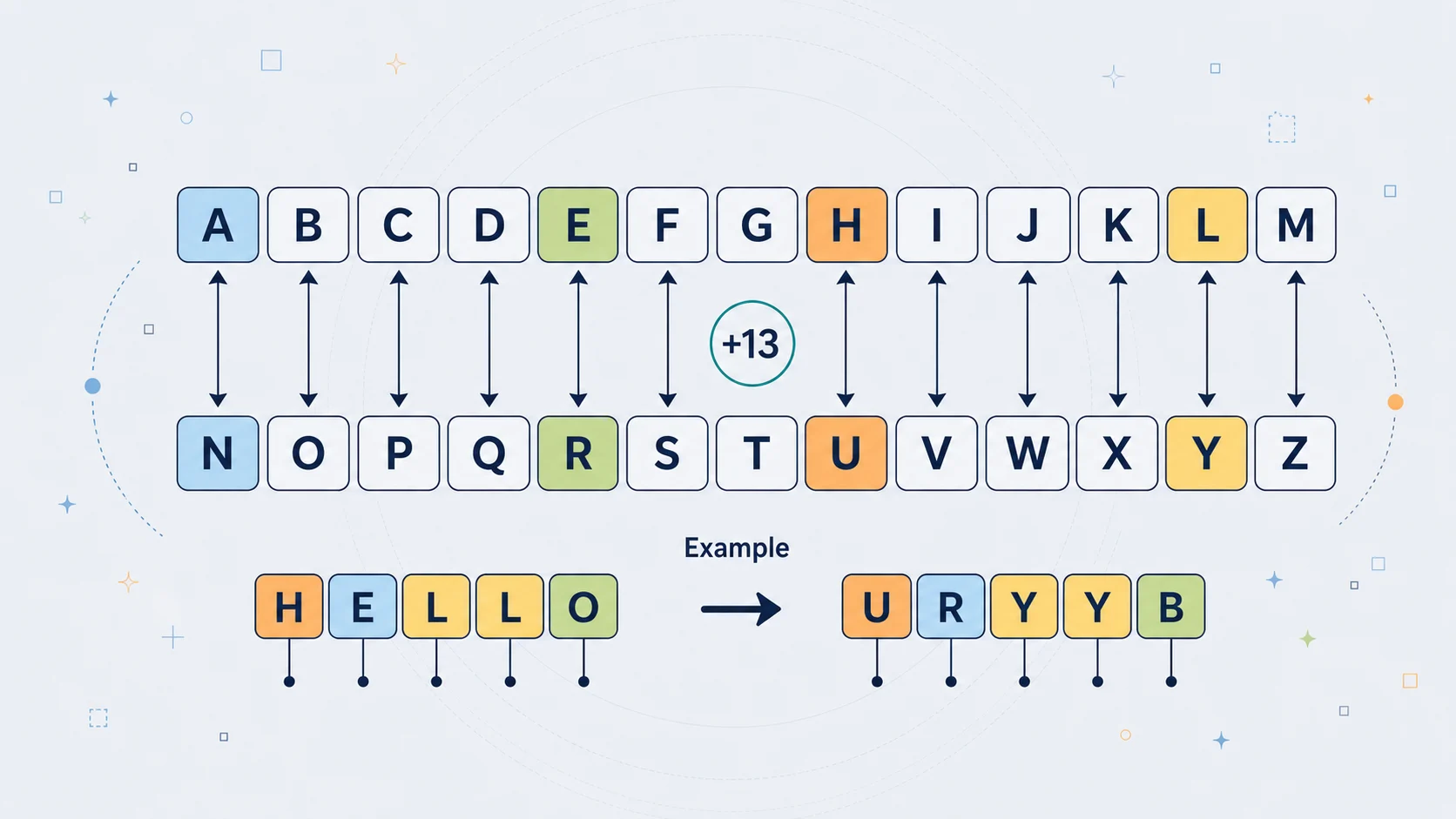
ROT13 works by taking each alphabetic character and moving it forward by 13 positions. The alphabet is treated as circular, so once the shift goes past Z, it loops back to A.
You can picture it like this:
Plain: ABCDEFGHIJKLMNOPQRSTUVWXYZ
ROT13: NOPQRSTUVWXYZABCDEFGHIJKLM
The top row is the ordinary alphabet. The bottom row shows the ROT13 substitution. To encode a letter, you find it in the top row and replace it with the one directly below. To decode, you do exactly the same thing again.
So:
A -> NB -> OC -> PH -> UM -> ZN -> AT -> GZ -> M
Lowercase letters work the same way:
a -> nh -> uz -> m
Most implementations preserve the original case, so uppercase stays uppercase and lowercase stays lowercase. Non-letter characters such as spaces, punctuation, digits, and symbols are usually left unchanged. That means a sentence keeps its overall structure even after being transformed.
For example:
Hello, World!
becomes:
Uryyb, Jbeyq!
The comma, space, and exclamation mark remain as they are. Only the letters move.
The most important mechanical fact about ROT13 is that it is self-inverse. In more ordinary language, this means that if you apply ROT13 twice, you get the original text back. That happens because moving 13 places twice is the same as moving 26 places in total, and moving 26 places in a 26-letter alphabet brings you right back to where you started.
So:
$$ \operatorname{ROT13}(\operatorname{ROT13}(\text{text})) = \text{text} $$
That property is what makes ROT13 feel so neat. In most ciphers, encryption and decryption are separate procedures. In ROT13, they are the same procedure.
Shift, Structure, and Rules
Unlike a general Caesar cipher, ROT13 does not give the user any choice of shift. In its standard form, the rotation is always fixed at 13. That fixed shift is effectively the entire rule of the cipher.
So the key and rules can be stated very simply.
The first rule is that only letters are transformed. Characters outside the alphabet are usually left unchanged.
The second rule is that every letter is shifted exactly 13 places.
The third rule is that the alphabet wraps around, so the shift continues from the end back to the beginning.
The fourth rule is that case is usually preserved, meaning uppercase letters become uppercase letters and lowercase letters become lowercase letters.
The fifth rule is that encryption and decryption are identical. There is no separate reverse procedure to learn. The same mapping undoes itself.
Because the shift is fixed, ROT13 has no real secrecy in the usual cryptographic sense. If someone knows the text has been encoded with ROT13, they do not need a hidden key from the sender. They simply apply ROT13 again. Even if they do not know that ROT13 was used, the small scale of the transformation makes it very easy to identify and reverse.
This is why it is more accurate to describe ROT13 as a standardised alphabet rotation than as a secure keyed cipher. It is useful as a teaching tool because the rule is easy to grasp and easy to implement, but that simplicity is also exactly why it offers no real protection.
A Simple Example
Take the plaintext:
HELLO WORLD
Now transform each letter one at a time:
H -> UE -> RL -> YL -> YO -> B
So HELLO becomes URYYB.
Now the second word:
W -> JO -> BR -> EL -> YD -> Q
So WORLD becomes JBEYQ.
The full result is:
HELLO WORLD -> URYYB JBEYQ
Now apply ROT13 again to the ciphertext:
U -> HR -> EY -> LY -> LB -> O
and:
J -> WB -> OE -> RY -> LQ -> D
So:
URYYB JBEYQ -> HELLO WORLD
That single example shows the whole cipher in action. The same mapping both scrambles and restores the text.
Here is another example with punctuation and mixed case:
Hello, Cryptography!
becomes:
Uryyb, Pelcgbtencul!
Again, the punctuation and spacing stay the same. Only the letters rotate.
You can also see the reciprocal nature of the cipher in single-letter pairs:
Every pair works in both directions.
Where It Came From
ROT13 is historically connected to the much older Caesar cipher, but it should not be confused with Caesar's actual method. Julius Caesar is associated with a fixed letter shift in ancient Rome, usually described as a shift of 3. ROT13 is a later, modern variant that borrows the same general idea of rotating letters through the alphabet.
The specific form now known as ROT13 became well known in early online culture, particularly on Usenet and in related computing communities. In that environment, people often wanted a way to hide text without seriously encrypting it. They used it to obscure joke punchlines, puzzle answers, spoilers, and material that some readers might not want to see immediately. ROT13 was perfect for that purpose because it was simple, standard, and easy to reverse if the reader chose to do so.
That last point matters. ROT13 was not primarily about keeping outsiders out. It was about requiring a small act of intention from the reader. Instead of being forced to see a spoiler or offensive joke at once, the reader had to make a conscious choice to decode it. In that sense, ROT13 served as a kind of courtesy veil rather than a lock.
It became especially common in internet communities because it was easy to support technically. Since it only transforms ordinary letters into other ordinary letters, it did not introduce unusual symbols that might break software or cause display problems. Many Unix-like systems could perform it with a simple transliteration command, and some newsreaders eventually built ROT13 decoding directly into the interface.
Over time, ROT13 became part of internet folklore. It appeared in jokes, programming culture, puzzle communities, and discussions of weak encryption. It also became a kind of cultural shorthand. Calling something "basically ROT13" came to mean that it was laughably insecure.
There are also a few historical curiosities associated with it. ROT13 has appeared in software tools, editor commands, programming exercises, joke papers, and even some real systems where weak obfuscation was used in places where proper security should have been used. Those cases helped cement its reputation as the classic example of something that looks like encryption while offering almost no real protection.
Why People Used It
Although ROT13 is cryptographically weak, it was useful for a different reason: it solved a social problem very cheaply.
In early online spaces, people often wanted to post information that should not be seen accidentally. A joke punchline might be ruined if read too soon. A puzzle answer might spoil the challenge. A discussion of a film, novel, or television episode might reveal an important twist. A mildly offensive or sensitive remark might be acceptable if hidden behind a voluntary barrier but annoying if displayed in plain sight.
ROT13 gave communities a lightweight way to handle this. It did not pretend to provide real confidentiality. Instead, it created a small, deliberate pause between the text and the reader. The reader had to choose to decode it. That was often enough.
Its usefulness also came from its simplicity. Everyone could learn the rule quickly. Programmers could implement it in a few lines. Editors and shell tools could support it easily. Readers did not need a secret password or a specialised system. The same transformation worked in both directions, so there was very little to remember.
This made ROT13 ideal for hiding joke punchlines, obscuring spoilers in online discussion, concealing puzzle answers, lightly masking text from casual glance, teaching basic substitution ciphers, and serving as an early cryptography exercise in programming.
It also became useful in education because it is simple enough to understand fully. Many stronger ciphers require more mathematical machinery, more background knowledge, or more complicated key handling. ROT13 lets beginners see the core idea immediately: plaintext becomes ciphertext through a repeatable transformation. That alone makes it valuable as a teaching device.
So while ROT13 was never useful in the sense of protecting secrets from attackers, it was useful in a narrower and very real sense. It gave people a shared, low-friction convention for voluntary obscuring.
Its Obvious Weaknesses
ROT13 has severe weaknesses, and these are not minor technical issues. They are fundamental to the design.
The biggest weakness is that the shift is fixed. There is no meaningful secret key to protect. If the reader knows ROT13 is being used, the message can be reversed immediately by applying the same transformation again.
Even if the reader does not know ROT13 is being used, it is still one of the easiest possible ciphers to break. It belongs to the Caesar family, which already has a tiny keyspace. A general Caesar cipher has only 25 non-trivial shifts to test. ROT13 fixes one of them permanently. That means the uncertainty is almost nonexistent.
Another weakness is that ROT13 preserves the overall structure of the message. Word lengths remain the same. Spaces remain in the same places. Punctuation usually stays untouched. Capitalisation patterns often survive. Repeated words remain repeated, just in transformed form. All of this leaks information.
For example, if a three-letter word appears over and over, it is probably a common word such as the or and. A cryptanalyst barely has to work to exploit patterns like that. In fact, human readers can often begin guessing words from context even before fully decoding the text.
It also fails completely against frequency analysis, the classic method for attacking substitution ciphers. In English, some letters appear much more often than others. Because ROT13 always maps the same letter to the same partner, those statistical patterns remain available to an attacker.
There is also a practical limitation: ROT13 only affects letters. Numbers, symbols, whitespace, and punctuation are usually passed through unchanged. If someone wants to obscure numeric information or more arbitrary data, standard ROT13 does not do much.
Finally, ROT13 can create a false sense of "encryption" for people who do not understand the difference between obfuscation and security. That is perhaps its most dangerous limitation. Used honestly, it is harmless and even useful. Used in place of real encryption, it is completely inadequate.
Why It Is So Easy to Defeat
ROT13 is so weak that "breaking" it is often barely the right word. In many cases, no real cryptanalysis is needed at all.
If you know the text has been encoded with ROT13, the solution is immediate: apply ROT13 again. That is enough to recover the original message. Since the cipher is reciprocal, the decoding process is identical to the encoding process.
Even if you do not know it is ROT13, there are several easy ways to uncover the plaintext.
The simplest is brute force across Caesar shifts. Since Caesar ciphers only use a limited number of shifts, you can try them one by one. With ROT13, one of those attempts will instantly reveal readable text. This takes almost no time by hand and virtually none by computer.
Another method is frequency analysis. Because ROT13 is a monoalphabetic substitution cipher, each plaintext letter always maps to the same ciphertext letter. That means English letter frequencies still shine through the disguise. Common letters such as E, T, A, and O leave visible statistical traces. Repeated short words also provide clues, as do familiar letter patterns.
Context matters too. Human readers are very good at spotting likely words. If you see something like gur, it often becomes obvious that the word is the. A short repeated word such as naq strongly suggests and. Once a few common words are recognised, the rest of the mapping falls into place rapidly.
That is why ROT13 is often decoded not by formal cryptanalysis but by casual recognition. It is transparent enough that many readers can solve chunks of it almost on sight after brief exposure. Some even learn to read short ROT13 phrases directly.
So the breaking process is trivial for three separate reasons: first, the transformation is fixed; second, the same operation reverses it; third, the structure of ordinary language leaks through the substitution.
A secure cipher should resist all of those problems. ROT13 resists none of them.
Ciphers in the Same Family
ROT13 belongs to a wider family of classical and semi-playful transformations.
The most obvious relative is the Caesar cipher. ROT13 is simply a Caesar cipher with a shift of 13. The difference is that ordinary Caesar ciphers can use other shifts, while ROT13 always uses the one exactly halfway around the alphabet.
Another related cipher is Atbash. Atbash is also a simple substitution cipher, but instead of shifting letters forward by a fixed amount, it mirrors the alphabet: A <-> Z, B <-> Y, C <-> X, and so on. Like ROT13, Atbash is reciprocal and easy to reverse.
There are also general monoalphabetic substitution ciphers, where each letter is replaced by some other letter according to a full alphabet permutation rather than a simple shift. These are more flexible than ROT13, but they are still vulnerable to frequency analysis.
From there, the family becomes more sophisticated. Vigenere improves on Caesar-style shifts by changing the shift throughout the message according to a keyword. That makes pattern analysis harder and represents a real step upward from ROT13 and simple Caesar systems.
A few variants are specifically inspired by ROT13 itself:
ROT5applies a similar idea to digits, rotating0-9by 5 places.ROT18combines ROT13 for letters with ROT5 for numbers.ROT47extends the idea to a wider range of printable ASCII characters, including punctuation and symbols.
These variants are more thorough in terms of obfuscation, but they still do not provide serious security. They are extensions of the same basic idea, not modern cryptography.
So ROT13 sits in an interesting place. It is related backwards to ancient substitution ciphers such as Caesar and Atbash, sideways to other simple rotation schemes, and forwards to more complex systems that were invented because simple substitution proved too weak.
Why ROT13 Still Deserves a Place
ROT13 still matters, not because it is secure, but because it teaches several important lessons unusually well.
First, it is one of the clearest demonstrations of what a cipher actually does. It takes readable text and transforms it according to a rule. That alone makes cryptography feel less abstract for beginners.
Second, it shows the difference between obscuring information and protecting it. This is a crucial distinction. ROT13 can hide text from casual glance, but it cannot defend it from any serious attempt to read it. Understanding that gap is one of the first steps toward understanding real security.
Third, it illustrates a beautiful mathematical idea: a transformation can be its own inverse. Because the alphabet has 26 letters and 13 is exactly half of 26, applying the same operation twice restores the original. That makes ROT13 a particularly elegant teaching example.
Fourth, it has genuine historical and cultural value. It belongs to the story of early internet life, Usenet etiquette, programming culture, spoiler-hiding conventions, and the long tradition of playful amateur cryptography. It is part of how online communities learned to handle visibility, consent, humour, and technical ingenuity.
Finally, ROT13 matters because simple things are often the best way to begin. Before modern cryptography can make sense, it helps to understand substitution, reversibility, letter mapping, wrapping, brute force, and frequency leakage. ROT13 puts all of those ideas in a form that can be grasped almost immediately.
So although it has no place in real security, it still has a place in learning, in internet culture, and in the history of how people have tried to hide meaning in plain sight. In that limited but genuine way, ROT13 remains worth knowing.
ROT13 in Python
Because ROT13 is so small and self-contained, it is one of the best ciphers for showing how a real implementation works. A beginner can read the code without too much strain, and almost every line corresponds directly to one of the rules already described in the article. That makes it a useful bridge between the idea of the cipher and the practical act of building it.
The main task is simple: go through the text character by character, check whether each character is an uppercase letter, a lowercase letter, or something else, and then apply the appropriate action. Letters are rotated by 13 places through the alphabet, while punctuation, spaces, and numbers are left unchanged. Because ROT13 is reciprocal, the same function can be used for both encoding and decoding.
def rot13(text):
result = []
for char in text:
if 'A' <= char <= 'Z':
result.append(chr((ord(char) - ord('A') + 13) % 26 + ord('A')))
elif 'a' <= char <= 'z':
result.append(chr((ord(char) - ord('a') + 13) % 26 + ord('a')))
else:
result.append(char)
return ''.join(result)
message = "Hello, World!"
encoded = rot13(message)
decoded = rot13(encoded)
print("Original:", message)
print("Encoded: ", encoded)
print("Decoded: ", decoded)
If this code is run, the output will be:
Original: Hello, World!
Encoded: Uryyb, Jbeyq!
Decoded: Hello, World!
The most important part of the function is the arithmetic inside the letter-handling lines. For uppercase letters, the code first converts the character into its numerical code using ord(). It then shifts the letter into a zero-based alphabet position by subtracting ord('A'). Once the letter is expressed as a number from 0 to 25, it adds 13, uses % 26 to wrap around if necessary, and then converts the result back into a letter with chr().
That wrapping step matters. Without it, letters near the end of the alphabet would go out of range. With % 26, the alphabet behaves like a loop rather than a straight line. So W can move forward by 13 places and wrap back around to become J, and Z can wrap back around to become M.
The lowercase branch works in exactly the same way, except that it uses a instead of A. This preserves case automatically. An uppercase letter becomes another uppercase letter, and a lowercase letter becomes another lowercase letter. Everything that is not alphabetic falls into the else clause and is copied unchanged. That is why commas, spaces, and exclamation marks survive intact in the output.
This small example also demonstrates the defining property of ROT13 more clearly than almost any verbal explanation: the same function can be applied twice. The first pass transforms plaintext into ROT13 text, and the second restores the original. In other words, there is no separate decryption routine because the cipher undoes itself.
For that reason, ROT13 is often used as an early programming exercise. It is short enough to fit on a page, but rich enough to teach several useful ideas at once: character handling, code points, modular arithmetic, conditional logic, iteration, and the relationship between mathematical rules and actual code.
In a more serious cryptographic system, the code would be much more complicated, the key would matter enormously, and the same simple reversibility would no longer be a sign of elegance but a sign of weakness. With ROT13, however, that simplicity is exactly what makes it such a good teaching example. It allows the reader to see, in a very direct way, how a cipher can be turned from a rule on paper into a working piece of software.