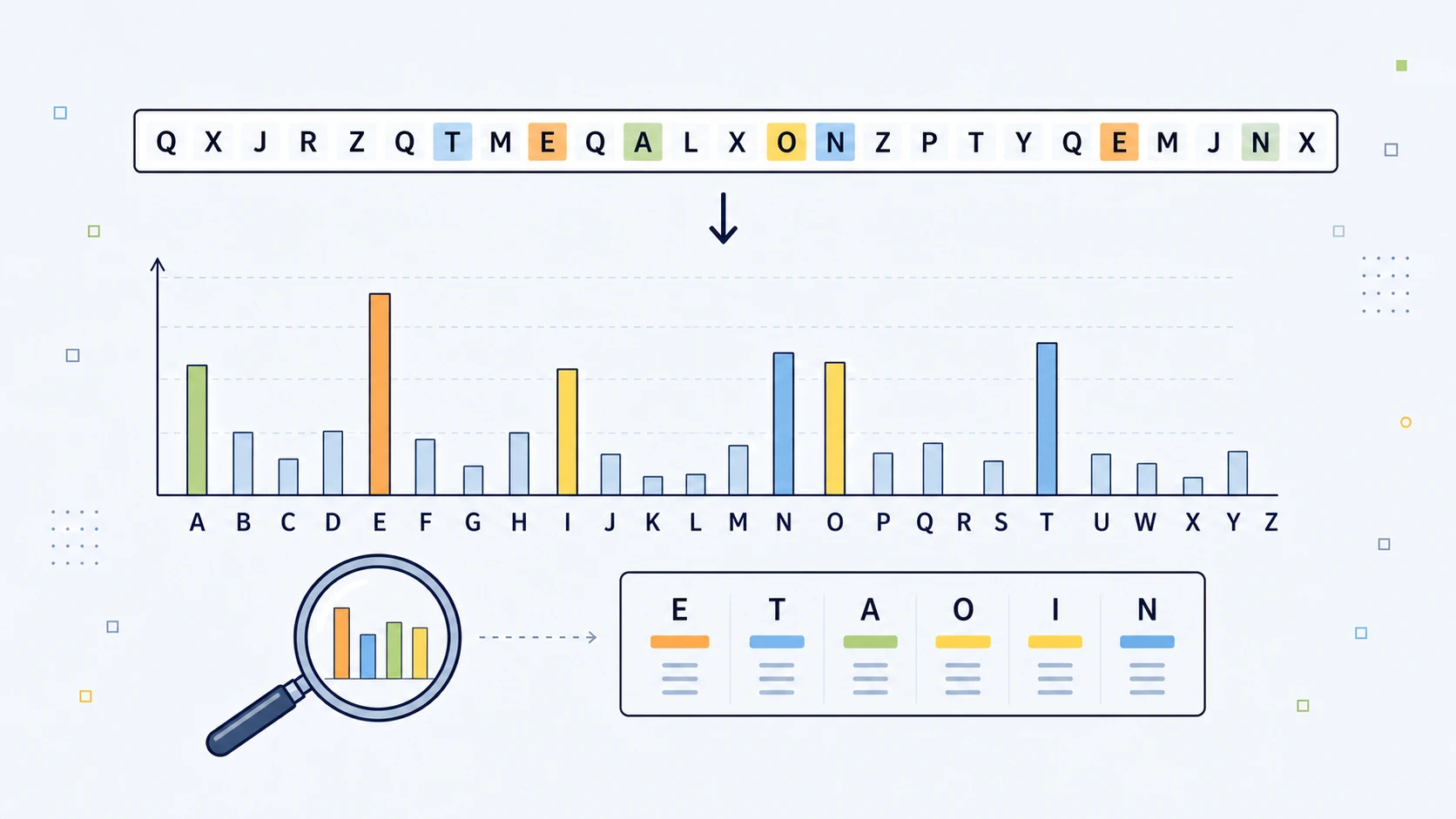
Frequency analysis is one of the simplest and most important ideas in classical cryptanalysis: count what appears often, compare it with the habits of normal language, and use the mismatch to begin breaking weak ciphers. It is especially powerful against Caesar, ROT13, and monoalphabetic substitution ciphers, because those systems change the letters but often leave the statistical shape of the original message behind.
The Moment a Cipher Stops Looking Like Magic
At first glance, ciphertext looks like chaos. A page of capital letters, stripped of punctuation and spaces, has the theatrical appearance of secrecy. It seems to have escaped ordinary language entirely:
WKH TXLFN EURZQ IRA MXPSV RYHU WKH ODCB GRJ
But many classical ciphers only disguise language. They do not destroy its habits.
English is not random. The letter E appears far more often than Q. The pair TH is much more common than ZX. Some short words appear again and again. Letters clump, repeat, avoid each other, and form recognisable shapes.
A cipher that preserves these patterns is vulnerable, even if every visible letter has been changed.
Frequency analysis is the study of how often letters, symbols, pairs of letters, triples of letters, and other patterns occur in a ciphertext. It does not necessarily require the key. It does not always require knowing the exact cipher. It begins with a simpler question: what does this ciphertext do often?
That question changed the history of cryptography. It turned codebreaking from a matter of intuition into a repeatable statistical method. Once cryptanalysts learned to count letters and compare them with the expected habits of natural language, simple substitution ciphers could no longer be trusted.
Frequency analysis is not a cipher. It is a weapon against ciphers.
Language Has a Statistical Shape
Every written language has a statistical texture.
In English, a typical order of common letters begins roughly:
E T A O I N S H R D L U ...
This is why the old sequence ETAOIN SHRDLU became famous. It reflects the high-frequency letters of English, though the exact order changes from sample to sample.
A long English passage will usually contain many examples of these patterns:
| Pattern type | Common examples |
|---|---|
| Single letters | E, T, A, O, I, N, S, H |
| Bigrams | TH, HE, IN, ER, AN, RE, ON |
| Trigrams | THE, AND, ING, ION, ENT |
| Short words | the, and, of, to, in, is, it |
The crucial point is that many classical ciphers preserve some part of this structure.
A Caesar cipher shifts every letter by the same amount. If E becomes H, then every E becomes H. If the original message contained many Es, the ciphertext will contain many Hs. The frequency peak has moved, but the peak still exists.
A monoalphabetic substitution cipher does the same thing in a more general way. It might replace:
E -> X
T -> Q
A -> M
But the mapping is still fixed. Every plaintext E still becomes the same ciphertext letter. That means the statistical fingerprint remains visible.
The cipher has changed the labels. It has not erased the distribution.
The Basic Attack: Count, Compare, Guess, Test
Frequency analysis begins with counting.
A cryptanalyst takes the ciphertext and counts how often each letter appears. A small table might look like this:
| Cipher letter | Count | Possible plaintext guess |
|---|---|---|
X |
47 | E or T |
L |
34 | T, A, O, or H |
I |
31 | A, O, I, or N |
E |
28 | Common plaintext letter |
Q |
3 | Less likely to be E |
If X is the most common ciphertext letter, a first guess might be:
X -> E
But this is only a hypothesis.
English letter frequency is not a law of nature. In one passage, T might beat E. In another, the subject matter may produce unusual letters. A short message can be wildly misleading. A sentence about jazz quizzes will not have the same distribution as a paragraph from a Victorian novel.
So the cryptanalyst does not simply replace the most common ciphertext letter with E and declare victory. That is the beginner version of frequency analysis, not the real method.
A more realistic process looks like this:
- Count the letters.
- Compare the distribution with expected English frequencies.
- Make provisional guesses.
- Look for common bigrams and trigrams.
- Search for repeated words and word shapes.
- Use partial plaintext to infer more mappings.
- Backtrack when a guess produces nonsense.
Frequency analysis is partly mathematics and partly linguistic judgement. The statistics point towards likely doors. Human judgement, or a more advanced algorithm, decides which doors actually open.
Frequencies, Proportions, and Expected Counts
The simplest mathematical idea behind frequency analysis is the difference between an observed frequency and an expected frequency.
Suppose a ciphertext contains $N$ letters. Let:
| Symbol | Meaning |
|---|---|
| $n_E$ | number of times E appears |
| $N$ | total number of letters |
Then the observed frequency of E is:
$$ \frac{n_E}{N} $$
If a 1,000-letter passage contains 127 Es, then:
$$ \frac{127}{1000} = 0.127 $$
So E makes up:
$$ 12.7\% $$
of the text.
In ordinary English, E is often around 12-13% of letters, depending on the sample. So if a decrypted candidate has E at roughly that level, that is one small sign that the candidate may be English-like.
But frequency analysis does not rely on one letter alone. It compares the whole distribution.
For each letter, we can ask:
- How many times did this letter appear?
- How many times would we expect it to appear in normal English?
- How large is the difference?
That is the bridge from simple counting to statistical cryptanalysis.
Caesar Cipher: When the Whole Alphabet Slides
The Caesar cipher is the easiest place to see frequency analysis in action.
Suppose we have this ciphertext:
WKH TXLFN EURZQ IRA MXPSV RYHU WKH ODCB GRJ
A reader familiar with Caesar examples might already suspect a shift of 3, because WKH often decrypts to THE.
But frequency analysis gives us a more systematic route.
In a Caesar cipher, the whole alphabet is shifted by the same amount. With a shift of 3:
A -> D
B -> E
C -> F
D -> G
...
X -> A
Y -> B
Z -> C
To decrypt, we shift backwards:
W -> T
K -> H
H -> E
So:
WKH -> THE
The full message becomes:
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
For Caesar ciphers, there are only 26 possible shifts, including the identity shift of 0. Only 25 of them actually change the text.
That means a computer can simply try every possible shift and score the results. The correct one will usually look much more English-like than the others.
This is where frequency analysis becomes beautifully mechanical:
- Try every shift.
- Measure how English-like each result is.
- Choose the best-scoring candidate.
Chi-Squared Scoring: A Cleaner Way to Crack Caesar
A simple Caesar cracker can show all 26 shifts and let the user choose the readable one. But a better method is to score each candidate mathematically.
One common method is the chi-squared score.
For each letter, compare:
- the observed count in the candidate plaintext
- the expected count in ordinary English
The formula is:
$$ \chi^2 = \sum \frac{(O_i - E_i)^2}{E_i} $$
where:
| Symbol | Meaning |
|---|---|
| $O_i$ | observed count of letter $i$ |
| $E_i$ | expected count of letter $i$ |
| $\sum$ | add the value for all 26 letters |
If the candidate plaintext has 200 letters, and English normally has about 12.7% Es, then the expected number of Es is:
$$ E_E = 0.127 \times 200 = 25.4 $$
If the candidate actually contains 24 Es, then the contribution from E is:
$$ \frac{(24 - 25.4)^2}{25.4} = \frac{1.96}{25.4} \approx 0.077 $$
That is a small contribution, because 24 is close to 25.4.
But if a candidate contains only 3 Es, then:
$$ \frac{(3 - 25.4)^2}{25.4} = \frac{501.76}{25.4} \approx 19.75 $$
That is much worse.
The lower the total chi-squared score, the more closely the candidate resembles ordinary English letter frequencies.
For Caesar cracking, the algorithm is:
- Try shift 0.
- Count the letters in the candidate plaintext.
- Compare those counts with English frequencies.
- Compute the chi-squared score.
- Repeat for all 26 shifts.
- Choose the shift with the lowest score.
This is not perfect, especially for short messages. But it is a clean and useful method. The computer is no longer merely displaying possible decryptions. It is ranking hypotheses.
Why Short Messages Are Dangerous
Frequency analysis becomes more reliable as the sample gets longer.
This is because short texts are noisy. They may not resemble the average behaviour of English.
Consider:
ATTACK AT DAWN
Ignoring spaces, this gives:
ATTACKATDAWN
This short message contains many As and Ts, but no E at all. A naive frequency attack might be badly misled.
That does not mean frequency analysis is useless on short texts. It means the confidence should be lower. A tool should not pretend to have "cracked" a message merely because one frequency score is slightly better than another.
A good frequency-analysis tool should distinguish between:
| Result type | Meaning |
|---|---|
| High confidence | The plaintext is readable and the score is clearly best |
| Medium confidence | One candidate scores best, but the sample is short |
| Low confidence | There are clues, but not enough text to be sure |
| Preview only | The tool is showing a possible direction, not a solved plaintext |
This distinction matters. Caesar can often be cracked automatically. A general substitution cipher usually cannot be solved completely by simple frequency ranking alone.
Beyond Single Letters: Bigrams, Trigrams, and Word Shapes
Single-letter frequency is powerful, but it is not the whole method.
Natural language contains patterns larger than one letter.
In English:
Qis usually followed byUHoften appears afterT,S,C,P, orWTHEis extremely commonINGappears constantly- double letters such as
LL,SS,EE, andOOappear in recognisable places
These larger patterns give the cryptanalyst extra leverage.
Bigrams: The Power of Pairs
A bigram is a pair of letters.
Common English bigrams include:
TH, HE, IN, ER, AN, RE, ON, AT, EN, ND
If a ciphertext contains the repeated bigram XL again and again, and the most common trigram is XLI, a cryptanalyst might guess:
XLI -> THE
That would imply:
X -> T
L -> H
I -> E
That single guess can unlock a surprising amount of the message.
Bigrams are especially useful because they contain more structure than individual letters. The letter T is common, but TH is much more distinctive.
Trigrams: When Three Letters Give the Game Away
A trigram is a group of three letters.
Common English trigrams include:
THE, AND, ING, ENT, ION, HER, FOR, THA
Trigrams are often more revealing than single letters because they carry more linguistic information.
For example, a repeated three-letter ciphertext word in a simple substitution cipher may correspond to:
THE
AND
YOU
or it may be part of a longer word such as:
THAT
depending on spacing and context.
If word spaces have been preserved, the attack becomes easier. If spaces have been removed, the cryptanalyst must work harder, but repeated trigrams still matter.
Word Shapes: Repetition Without Knowing the Letters
A word shape records the pattern of repeated letters without caring what the actual letters are.
| Word | Shape |
|---|---|
THAT |
ABAC |
MEET |
ABBC |
HELLO |
ABCCD |
PEOPLE |
ABCADB |
ATTACK |
ABBCDE |
This is useful because substitution ciphers preserve repeated-letter structure.
If a ciphertext word has the shape:
XYYZ
then its shape is:
ABBC
So the plaintext must also have the shape ABBC. It might be:
MEET
SEEN
NOON
BOOK
It cannot be:
FROM
THAT
MAKE
because those words have different repetition patterns.
Word shapes become especially useful when combined with frequency clues. If a common four-letter ciphertext word has the shape ABBC, and the surrounding partial plaintext suggests a verb or noun, the list of possibilities narrows quickly.
Frequency analysis becomes much stronger when these clues are combined.
Monoalphabetic Substitution: A Huge Keyspace with a Fatal Leak
In a simple monoalphabetic substitution cipher, each plaintext letter is replaced by a different ciphertext letter.
For example:
A -> Q
B -> M
C -> Z
D -> R
E -> X
...
Unlike Caesar, the alphabet has not merely shifted. It has been scrambled.
The number of possible substitution alphabets is enormous:
$$ 26! $$
That means:
$$ 26 \times 25 \times 24 \times \cdots \times 3 \times 2 \times 1 $$
which equals:
403,291,461,126,605,635,584,000,000
That is more than 400 septillion possible alphabets.
So brute-forcing a general substitution cipher by trying every possible key is not realistic by hand, and not a sensible beginner method even with a computer.
But the cipher has a fatal weakness: each plaintext letter always becomes the same ciphertext letter.
If plaintext E becomes ciphertext X, then every E becomes X.
So the ciphertext distribution still resembles the plaintext distribution, only relabelled.
A typical attack might begin like this:
Ciphertext frequency:
X is most common
L is second most common
I is third most common
Common English letters:
E, T, A, O, I, N
A first guess might be:
X -> E
L -> T
I -> A
But the cryptanalyst quickly checks whether those guesses produce recognisable fragments.
If a repeated ciphertext group becomes something like:
T?E
that might suggest:
THE
If a one-letter ciphertext word appears frequently, it is probably A or I. If a three-letter word appears constantly, it may be THE or AND.
The method is iterative:
- Frequency suggests guesses.
- Guesses reveal partial words.
- Partial words suggest more mappings.
- New mappings reveal more text.
- Bad guesses create contradictions.
- Contradictions force revision.
That is why frequency analysis is not simply "replace the most common letter with E". Real cryptanalysis combines counting, probability, word structure, language knowledge, and repeated correction.
Al-Kindi and the Birth of Systematic Cryptanalysis
The first known systematic explanation of frequency analysis is usually credited to Al-Kindi, the 9th-century Arab polymath.
His work on deciphering encrypted messages marks one of the great turning points in the history of cryptography.
Before this kind of analysis, secret writing could be treated as a craft of clever disguises. A substitution alphabet looked secure because the message was unreadable to the casual observer. Al-Kindi's insight was that a message could be attacked through the statistical habits of its language.
That was a major conceptual leap.
Instead of asking only:
What rule did the sender use?
the cryptanalyst could ask:
What traces of the original language survived encryption?
This idea spread through later cryptographic practice. By the Renaissance and early modern period, European states were using and attacking substitution systems in diplomatic correspondence. Cipher-making and cipher-breaking became part of statecraft.
Every improvement in secrecy invited an improvement in analysis.
Frequency analysis helped create the arms race at the centre of cryptographic history:
Code-makers try to hide patterns.
Code-breakers search for whatever patterns remain.
That arms race still defines cryptography today.
Why Frequency Analysis Was So Useful
Frequency analysis was powerful because it could work from ciphertext alone.
That matters.
In many historical situations, an attacker might have only an intercepted message. They might not know the key. They might not know the substitution alphabet. They might not know the exact content. But if they knew or suspected the language, they had a starting point.
Frequency analysis also scaled well by hand. It required patience, not advanced machinery. A careful person could count letters, mark repeated groups, list likely mappings, and gradually reconstruct the message.
It was especially useful against:
- Caesar shift ciphers
- Atbash-style fixed substitution
- keyword substitution ciphers
- general monoalphabetic substitution
- simple transposition ciphers, as a diagnostic clue
- some badly used homophonic systems
- parts of Vigenere-style ciphers once the key length was known
It also gave cryptanalysts diagnostic information.
Even when frequency analysis did not immediately decrypt a message, it could suggest what kind of cipher had been used.
A highly uneven frequency distribution might suggest:
- simple substitution
- transposition
- ordinary language with letters rearranged
A flatter distribution might suggest:
- polyalphabetic substitution
- compression
- encoding
- modern encryption
- random-looking data
Repeated groups might suggest:
- recurring plaintext
- repeated keys
- formulaic openings
- common words
So frequency analysis is both an attack and an investigative instrument.
The Limits: When Counting Letters Misleads You
Frequency analysis is powerful, but it is not magic.
The most common mistake is overconfidence. People learn that E is the most common letter in English, then assume the most common ciphertext symbol must represent E.
Sometimes it does. Often it does not.
Several things can weaken or defeat simple frequency analysis.
Short Messages
Short texts do not reliably follow normal language frequencies.
A 30-letter message may have no letter E at all. A short instruction such as:
ATTACK AT DAWN
has a very different distribution from a newspaper article or a chapter of a novel.
The shorter the ciphertext, the more random variation dominates.
In statistical terms, the sample size is too small. The observed frequencies have not had enough room to settle near their long-run averages.
Unusual Plaintext
The plaintext itself may be statistically strange.
Technical writing, poetry, names, lists, dialect, code words, and deliberately constrained writing can all distort the expected pattern.
A famous example is a lipogram: a text that deliberately avoids a particular letter.
A long English passage without the letter E would badly mislead a naive frequency attack.
Homophonic Substitution
A homophonic substitution cipher uses several possible ciphertext symbols for common plaintext letters.
Instead of always replacing E with X, it might replace E with:
X, 7, Q, M
according to a rule or choice.
This spreads out the frequency peak. The whole point is to stop E from creating one obvious ciphertext spike.
Homophonic substitution was historically important because it directly attacked the weakness exposed by frequency analysis.
Polyalphabetic Ciphers
A polyalphabetic cipher uses more than one substitution alphabet.
The Vigenere cipher is the classic example.
A plaintext E might encrypt to different ciphertext letters depending on its position and the current key letter.
This blurs the distribution. The same plaintext letter no longer produces the same ciphertext letter every time.
That makes simple frequency analysis much less effective.
Modern Encryption
Modern encryption is designed to destroy exactly the kind of statistical structure frequency analysis depends on.
Properly implemented encryption should produce ciphertext that looks random to an attacker who does not know the key. A frequency chart of raw encrypted bytes should not reveal the habits of English, French, Spanish, or any other plaintext language.
AES, ChaCha20, and modern hybrid encryption systems are not vulnerable to basic letter-counting attacks when used correctly.
If direct frequency analysis works against a supposed modern encryption system, something is badly wrong. The problem is likely not "frequency analysis is powerful enough to break modern crypto". The problem is more likely bad design, bad randomness, repeated keys, exposed metadata, predictable formatting, or an implementation mistake.
Vigenere: How Frequency Analysis Came Back Through the Side Door
The Vigenere cipher was designed to defeat ordinary frequency analysis.
Instead of using one fixed substitution alphabet, it uses multiple Caesar shifts controlled by a repeating keyword.
For example, with the key:
KEY
the shifts repeat like this:
K E Y K E Y K E Y ...
So the same plaintext letter can encrypt differently depending on where it appears.
That made Vigenere much stronger than simple substitution. For a long time, it had a reputation for being extremely difficult to break.
But the repeated keyword is also a weakness.
If the attacker can estimate the key length, the ciphertext can be split into separate streams. Each stream was encrypted with the same Caesar shift.
For a key length of 4, the attacker separates the ciphertext like this:
Column 1: letters 1, 5, 9, 13, ...
Column 2: letters 2, 6, 10, 14, ...
Column 3: letters 3, 7, 11, 15, ...
Column 4: letters 4, 8, 12, 16, ...
Each column can then be attacked like a Caesar cipher.
So Vigenere did not eliminate frequency analysis. It forced cryptanalysts to become more subtle.
The attack changed from:
Count the whole message.
to:
Estimate the key length.
Split the message into streams.
Count each stream separately.
Recover each Caesar shift.
This is a recurring pattern in cryptographic history. A defence hides one kind of structure, and the attack adapts by looking for another.
Index of Coincidence: Measuring How Uneven the Text Is
Another important tool connected with frequency analysis is the index of coincidence.
It measures the probability that two randomly chosen letters from a text are the same.
Suppose a text has:
| Symbol | Meaning |
|---|---|
| $N$ | total letters |
| $n_A$ | number of As |
| $n_B$ | number of Bs |
| $n_C$ | number of Cs |
and so on.
The index of coincidence is:
$$ I = \frac{\sum n_i(n_i - 1)}{N(N - 1)} $$
where the sum runs over all 26 letters.
The idea is simple:
- $n_i(n_i - 1)$ counts ordered pairs of matching letters of type $i$
- $N(N - 1)$ counts all possible ordered pairs of letters
- the ratio estimates the probability that two selected letters match
For random letters spread evenly across the alphabet, the probability of a match is about:
$$ \frac{127}{1000} = 0.127 $$0
For ordinary English, the value is usually higher, often around:
$$ \frac{127}{1000} = 0.127 $$1
depending on the text.
Why is English higher?
Because English is uneven. Some letters appear much more often than others. If E, T, A, and O are common, two randomly chosen letters are more likely to match than they would be in a perfectly even random alphabet.
This helps distinguish different kinds of ciphertext.
A monoalphabetic substitution cipher tends to preserve the unevenness of English. The letters have changed names, but the lumpy distribution remains.
A Vigenere cipher with a long or varied key tends to flatten the distribution, pushing the index of coincidence closer to random.
The index of coincidence does not automatically decrypt the message. It is more like a diagnostic reading. It helps answer questions such as:
- Does this look like language hidden by substitution?
- Does the distribution look too flat for monoalphabetic substitution?
- Might this be Vigenere or another polyalphabetic cipher?
- Is the sample long enough to say anything useful?
For a cryptanalysis tool, this is valuable. It tells the user whether frequency analysis is likely to be productive.
Related Ciphers and Techniques
Frequency analysis sits at the centre of many classical cryptography topics.
Caesar Cipher
The Caesar cipher shifts the alphabet by a fixed number.
Because there are only 26 possible shifts, it can be brute-forced easily. Frequency analysis gives a more elegant statistical attack, especially when combined with chi-squared scoring.
ROT13
ROT13 is a Caesar cipher with a fixed shift of 13.
It is not secure encryption. It is a simple text-obscuring method. Since applying ROT13 twice returns the original text, it is useful for hiding spoilers or puzzle answers, but not for protecting secrets.
Atbash Cipher
Atbash reverses the alphabet:
It is a fixed substitution cipher. Once recognised, it is trivial to reverse. Its frequency distribution remains the same shape as the original language, only mirrored through the alphabet.
Monoalphabetic Substitution
This is the classic target of frequency analysis.
Every plaintext letter maps to one ciphertext letter. The keyspace is enormous, but the statistical weakness is severe because the frequency pattern survives.
Keyword Substitution
A keyword substitution cipher builds a scrambled alphabet from a word or phrase.
For example, a keyword might be used to begin the cipher alphabet, with the remaining unused letters added afterwards.
But it is still monoalphabetic, so it remains vulnerable to frequency analysis.
Homophonic Substitution
Homophonic substitution was an attempt to defeat simple frequency analysis by assigning multiple ciphertext symbols to common plaintext letters.
It is stronger than basic substitution, but more complicated to use. If implemented badly, patterns may still leak.
Playfair Cipher
The Playfair cipher encrypts pairs of letters rather than single letters.
This changes the statistical problem. Single-letter frequency is less directly useful, but bigram patterns still matter. Playfair is harder than basic substitution, but it is still a classical cipher and not secure by modern standards.
Vigenere Cipher
Vigenere uses repeated-key polyalphabetic substitution.
Basic frequency analysis is weakened, but if the key length can be found, each stream can be attacked statistically.
Transposition Ciphers
A pure transposition cipher rearranges letters without changing them.
This means the single-letter frequency distribution is preserved exactly. The letters are the right letters; they are just in the wrong order.
Frequency analysis may show that the text is English-like, but it will not directly reveal the message. For transposition ciphers, the main problem is reconstructing the order.
Why Frequency Analysis Still Matters
Frequency analysis is not used to break modern encryption directly. Properly implemented modern encryption is built to resist this kind of statistical leakage.
But frequency analysis still matters for several reasons.
First, it explains why classical ciphers are insecure. Caesar, Atbash, and simple substitution do not merely feel old. They leak the structure of the plaintext.
Second, it introduces one of the deepest ideas in cryptography: secrecy fails when useful patterns survive.
The surface form of the message may change, but if exploitable structure remains, an attacker can use it.
Third, it is a superb teaching tool. Frequency analysis connects language, probability, statistics, algorithms, and history. It shows how a simple measurement can turn unreadable text into a solvable problem.
Fourth, the general principle has modern descendants. Real-world attacks often exploit leakage:
- repeated values
- biased randomness
- predictable formats
- metadata
- compression behaviour
- timing differences
- implementation mistakes
- reused keys or nonces
Modern cryptanalysis is vastly more advanced than counting letters, but the instinct is recognisably similar:
Find the pattern the system failed to hide.
That is why frequency analysis belongs on a cryptography site. It is not just an old codebreaking trick. It is one of the clearest demonstrations of what cryptanalysis is.
Python Example 1: Counting Letter Frequencies
Here is a simple Python function that counts letter frequencies in a piece of text.
Python exampleShow code
from collections import Counter
import string
ALPHABET = string.ascii_uppercase
def clean_letters(text):
"""Return only A-Z letters from the input text, converted to uppercase."""
return ''.join(char for char in text.upper() if char in ALPHABET)
def letter_frequencies(text):
"""Count each letter and return counts plus percentages."""
letters = clean_letters(text)
total = len(letters)
counts = Counter(letters)
results = []
for letter in ALPHABET:
count = counts.get(letter, 0)
percent = (count / total * 100) if total else 0
results.append((letter, count, percent))
return results
ciphertext = "WKH TXLFN EURZQ IRA MXPSV RYHU WKH ODCB GRJ"
for letter, count, percent in letter_frequencies(ciphertext):
if count > 0:
print(f"{letter}: {count:2d} {percent:5.2f}%")
This code removes spaces and punctuation, counts A-Z letters, and prints the percentage for each letter that appears.
For serious cryptanalysis, this count is only the first step. The next step is comparing those frequencies with expected English frequencies.
Python Example 2: Cracking Caesar with Chi-Squared Scoring
The following example tries all 26 Caesar shifts and scores each possible decryption against ordinary English letter frequencies.
Python exampleShow code
import string
from collections import Counter
ALPHABET = string.ascii_uppercase
ENGLISH_FREQ = {
'A': 8.17, 'B': 1.49, 'C': 2.78, 'D': 4.25, 'E': 12.70,
'F': 2.23, 'G': 2.02, 'H': 6.09, 'I': 6.97, 'J': 0.15,
'K': 0.77, 'L': 4.03, 'M': 2.41, 'N': 6.75, 'O': 7.51,
'P': 1.93, 'Q': 0.10, 'R': 5.99, 'S': 6.33, 'T': 9.06,
'U': 2.76, 'V': 0.98, 'W': 2.36, 'X': 0.15, 'Y': 1.97,
'Z': 0.07
}
def caesar_decrypt(text, shift):
"""Decrypt text by shifting letters backwards by shift places."""
output = []
for char in text:
upper = char.upper()
if upper in ALPHABET:
old_index = ALPHABET.index(upper)
new_index = (old_index - shift) % 26
new_char = ALPHABET[new_index]
if char.islower():
output.append(new_char.lower())
else:
output.append(new_char)
else:
output.append(char)
return ''.join(output)
def chi_squared_score(text):
"""Return a chi-squared score comparing text to English letter frequency."""
letters = ''.join(char for char in text.upper() if char in ALPHABET)
total = len(letters)
if total == 0:
return float('inf')
counts = Counter(letters)
score = 0
for letter in ALPHABET:
observed = counts.get(letter, 0)
expected = ENGLISH_FREQ[letter] / 100 * total
score += ((observed - expected) ** 2) / expected
return score
def crack_caesar(ciphertext):
"""Try every Caesar shift and return the candidates ranked by score."""
candidates = []
for shift in range(26):
plaintext = caesar_decrypt(ciphertext, shift)
score = chi_squared_score(plaintext)
candidates.append((score, shift, plaintext))
candidates.sort(key=lambda item: item[0])
return candidates
ciphertext = "WKH TXLFN EURZQ IRA MXPSV RYHU WKH ODCB GRJ"
results = crack_caesar(ciphertext)
best_score, best_shift, best_plaintext = results[0]
print("Best shift:", best_shift)
print("Score:", round(best_score, 2))
print("Plaintext:", best_plaintext)
print("\nTop candidates:")
for score, shift, plaintext in results[:5]:
print(f"Shift {shift:2d} | Score {score:7.2f} | {plaintext}")
Expected result:
Best shift: 3
Plaintext: THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
The code does not "understand" the sentence. It simply finds the shift whose letter distribution most closely resembles English.
For longer ciphertexts, this method becomes much more reliable.
Python Example 3: Counting Bigrams and Trigrams
Single letters are useful, but larger patterns can reveal more.
Python exampleShow code
from collections import Counter
import string
ALPHABET = string.ascii_uppercase
def clean_letters(text):
return ''.join(char for char in text.upper() if char in ALPHABET)
def ngram_counts(text, n=2):
"""Return the most common n-letter groups using a sliding window."""
letters = clean_letters(text)
groups = []
for i in range(len(letters) - n + 1):
groups.append(letters[i:i+n])
return Counter(groups).most_common()
ciphertext = "WKH WKH WKH DQG DQG WKDW WKDW WKDW"
print("Bigrams:")
for group, count in ngram_counts(ciphertext, 2)[:10]:
print(group, count)
print("\nTrigrams:")
for group, count in ngram_counts(ciphertext, 3)[:10]:
print(group, count)
This uses a sliding window.
For the text:
ABCDE
the bigrams are:
AB
BC
CD
DE
That is usually what you want for cryptanalysis, because overlapping patterns matter.
Python Example 4: Calculating the Index of Coincidence
The index of coincidence gives a rough measure of how uneven the letter distribution is.
Python exampleShow code
from collections import Counter
import string
ALPHABET = string.ascii_uppercase
def clean_letters(text):
return ''.join(char for char in text.upper() if char in ALPHABET)
def index_of_coincidence(text):
"""Calculate the index of coincidence for A-Z text."""
letters = clean_letters(text)
total = len(letters)
if total < 2:
return 0
counts = Counter(letters)
numerator = 0
for count in counts.values():
numerator += count * (count - 1)
denominator = total * (total - 1)
return numerator / denominator
texts = [
"THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG",
"QWERTYUIOPASDFGHJKLZXCVBNMQWERTYUIOP"
]
for text in texts:
print(text)
print("Index of coincidence:", round(index_of_coincidence(text), 4))
print()
For ordinary English, the value is often around:
0.065
For random letters over a 26-letter alphabet, it is closer to:
0.0385
The exact value depends heavily on text length. Short samples can jump around.
Python Example 5: A Rough Substitution Guess
This final example is deliberately modest.
It does not solve a substitution cipher. It simply maps the most common ciphertext letters to the most common English letters.
Python exampleShow code
from collections import Counter
import string
ENGLISH_ORDER = "ETAOINSHRDLCUMWFGYPBVKJXQZ"
ALPHABET = string.ascii_uppercase
def rough_substitution_guess(ciphertext):
"""Make a rough substitution guess using simple letter frequency order."""
letters = ''.join(char for char in ciphertext.upper() if char in ALPHABET)
counts = Counter(letters)
cipher_order = [letter for letter, count in counts.most_common()]
mapping = {}
for cipher_letter, plain_guess in zip(cipher_order, ENGLISH_ORDER):
mapping[cipher_letter] = plain_guess
output = []
for char in ciphertext:
upper = char.upper()
if upper in mapping:
guessed = mapping[upper]
output.append(guessed if char.isupper() else guessed.lower())
else:
output.append(char)
return ''.join(output), mapping
ciphertext = "LIVITCSWPIYVEWHEVSRIQMXLEYVEOIEWHRXEXIPFEMVE"
guess, mapping = rough_substitution_guess(ciphertext)
print("Rough plaintext guess:")
print(guess)
print("\nMapping guesses:")
for cipher_letter, plain_letter in mapping.items():
print(f"{cipher_letter} -> {plain_letter}")
This kind of output is often messy. That is expected.
A monoalphabetic substitution cipher usually needs iterative solving:
- frequency guesses
- word-shape clues
- repeated fragments
- partial plaintext
- corrections
- backtracking
The rough mapping is still useful because it gives the cryptanalyst somewhere to begin.
Reading the Results Honestly
A frequency-analysis tool should not overpromise.
It should make clear distinctions between different levels of confidence.
| Output | Meaning |
|---|---|
| Caesar cracked | A readable plaintext was found and the score strongly supports it |
| Likely Caesar shift | One shift scored best, but the text is short |
| Substitution clues found | Frequency mapping gives a starting point, not a solved message |
| Vigenere suspected | The distribution may be too flat for monoalphabetic substitution |
| Insufficient text | The sample is too short for reliable statistics |
| Unknown or non-English | The method may not apply well |
This distinction matters.
A Caesar cipher can be cracked automatically because every possible shift can be tested.
A general monoalphabetic substitution cipher is harder. Frequency analysis helps enormously, but it does not always produce complete plaintext without further solving.
For a public cryptography tool, honesty is part of quality. Users should understand whether the tool has actually decrypted something or merely produced a plausible lead.
The Central Lesson
Frequency analysis broke the illusion that secrecy comes from unreadable symbols alone.
A message can look scrambled and still leak its origin. It can hide the letters while preserving the habits of the language underneath.
That is the deeper lesson.
Classical ciphers often failed because they changed the appearance of language without destroying its statistical structure. Frequency analysis exposed that structure. It showed that every language has a fingerprint, and every weak cipher leaves part of that fingerprint behind.
Modern cryptography is vastly more sophisticated, but the principle remains alive: security depends on what an attacker can still measure.
A good cipher does not merely make text look strange. It removes useful patterns.
Frequency analysis is where many people first see that idea clearly. It is simple enough to do by hand, strong enough to break famous classical systems, and deep enough to introduce the statistical mindset behind cryptanalysis itself.
That is why counting letters changed the history of secret writing.